Intelligence System and Parallel Computer Architecture Lab
 Intelligence system and Parallel Computer Architecture (IP-CAL) Lab was founded in March 2021. Our lab is located in Ewha Womans University. Our research interests are Graphics Processing Units (GPU), machine learning accelerators, parallel programming, and computer architecture. Detailed research topics are described below. If you are interested in the topics, you are always welcome to visit our lab.
Intelligence system and Parallel Computer Architecture (IP-CAL) Lab was founded in March 2021. Our lab is located in Ewha Womans University. Our research interests are Graphics Processing Units (GPU), machine learning accelerators, parallel programming, and computer architecture. Detailed research topics are described below. If you are interested in the topics, you are always welcome to visit our lab.
Graphics Processing Unit (GPU) Micro-Architecture
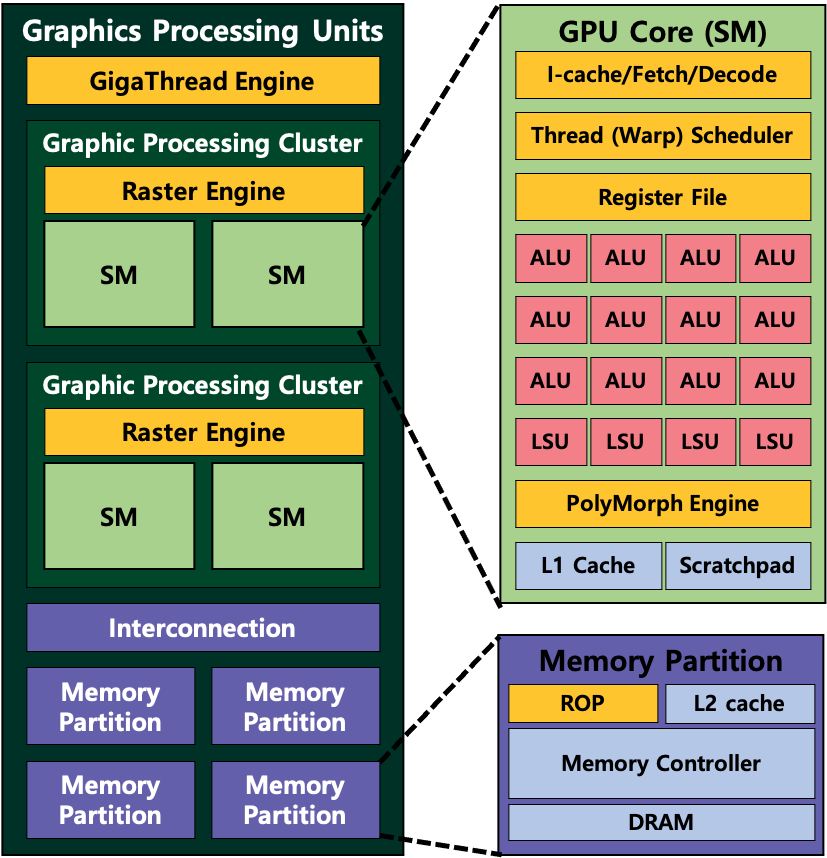 GPUs were first developed to accelerate graphics applications. Games are one major application that relies on the performance of GPUs. When the game application is launched, GPUs start to create 60~120 images every second using a massive number of GPU processors. This massive number of processors recently has begun to be used for general purpose applications such as machine learning algorithms, simulations, and many other applications instead of graphics applications. This paradigm is known as General-Purpose Computing on Graphics Processing Unit (GPGPU).
GPUs were first developed to accelerate graphics applications. Games are one major application that relies on the performance of GPUs. When the game application is launched, GPUs start to create 60~120 images every second using a massive number of GPU processors. This massive number of processors recently has begun to be used for general purpose applications such as machine learning algorithms, simulations, and many other applications instead of graphics applications. This paradigm is known as General-Purpose Computing on Graphics Processing Unit (GPGPU).
Our goal is to maximize the performance of GPUs when general-purpose applications such as machine learning algorithms, simulations, and many more are executed on the GPU hardware. We first identify the bottleneck points on the GPU architecture and propose a new modified architecture that can remove the bottleneck points. To verify our ideas, C/C++/Python based cycle-accurate simulations are used.
Ray Tracing Accelerator (RTA)
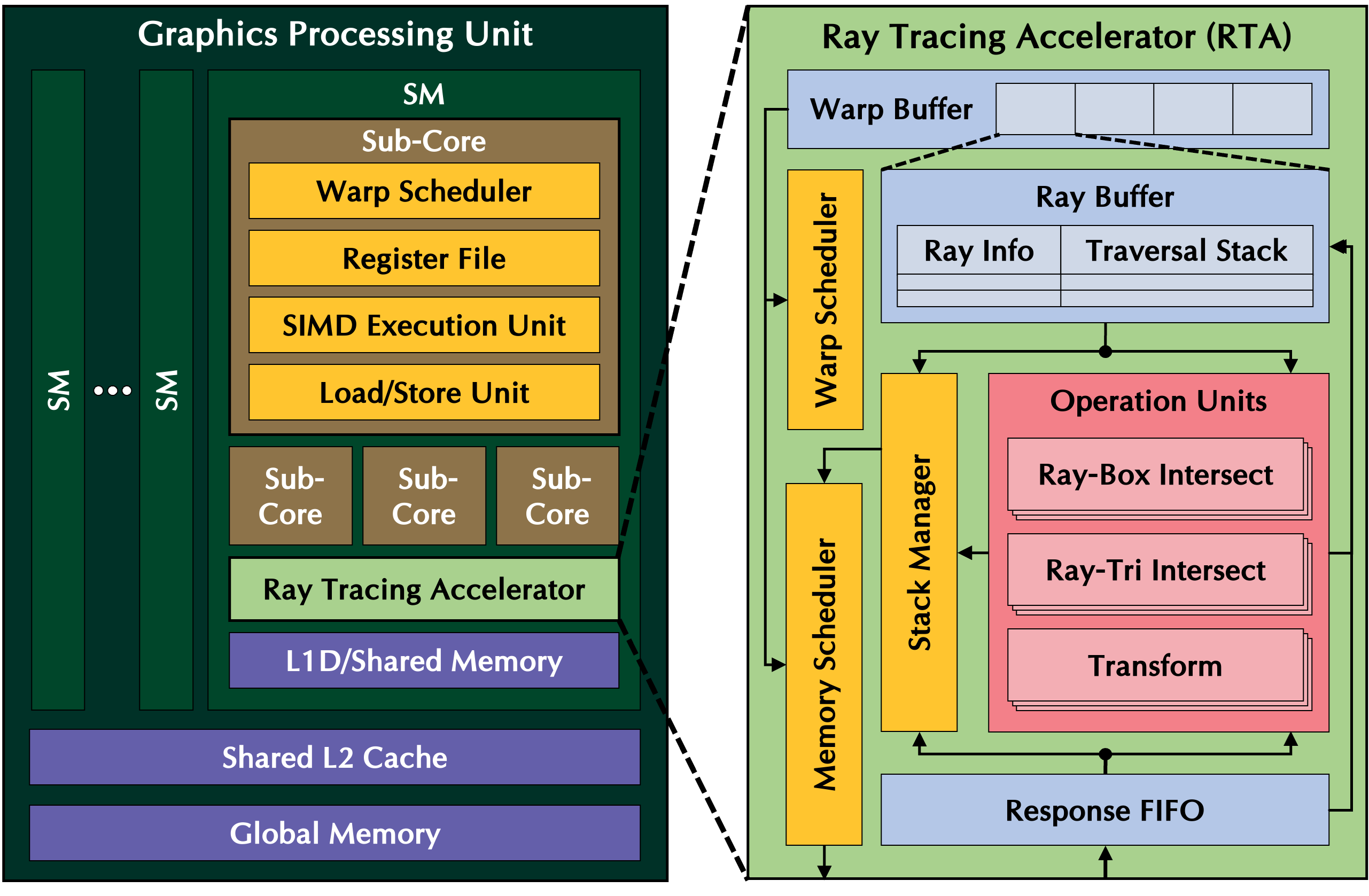 Ray tracing is a rendering technique that creates photorealistic images by simulating the physics of light rays as they travel and interact with objects in a 3D scene. It is widely used in high-end applications such as movies and Computer-Aided Design (CAD) and has recently gained popularity in real-time applications like video games. To enable real-time ray tracing, modern Graphics Processing Units (GPUs) feature specialized Ray Tracing Accelerators (RTAs) that efficiently handle tasks such as traversal and intersection.
Ray tracing is a rendering technique that creates photorealistic images by simulating the physics of light rays as they travel and interact with objects in a 3D scene. It is widely used in high-end applications such as movies and Computer-Aided Design (CAD) and has recently gained popularity in real-time applications like video games. To enable real-time ray tracing, modern Graphics Processing Units (GPUs) feature specialized Ray Tracing Accelerators (RTAs) that efficiently handle tasks such as traversal and intersection.
Our goal is to enhance GPU performance for ray tracing applications. We begin by analyzing the distinct characteristics of ray tracing workloads and identifying bottlenecks in GPU architecture, especially within RTAs. Based on the analysis, we propose an optimized architecture to improve ray tracing performance. To validate our approach, we use C/C++/CUDA based cycle-level simulators that support Vulkan, an industry-standard graphics API with ray tracing capabilities.
Machine Learning Accelerator
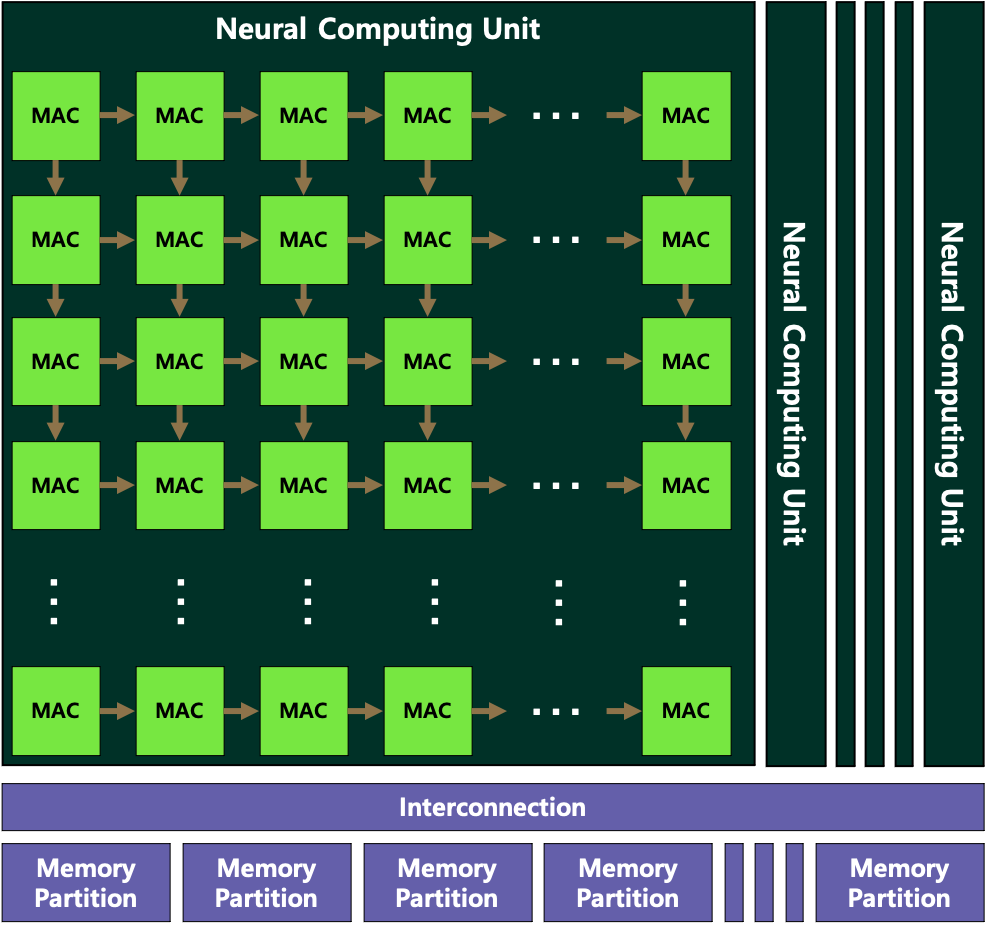 Machine learning algorithms have been applied in various areas such as image recognition, voice speech recognition, translation, text classification, and more. These algorithms are traditionally operated on Central Processing Units (CPUs) and Graphics Processing Units (GPUs). Especially, GPUs are widely used for the execution of applications. However, CPUs and GPUs are not designed for machine learning algorithms, there have been several issues in terms of performance and power consumption. To resolve the problems, various machine learning accelerator designs have been proposed by researchers. One famous design is using a systolic array that has many small processing units which are only designed to perform Multiply-And-Accumulate (MAC) operations. These small processing units are connected only to their neighbor so that the data can be transferred from one processing unit to the other processing unit.
Machine learning algorithms have been applied in various areas such as image recognition, voice speech recognition, translation, text classification, and more. These algorithms are traditionally operated on Central Processing Units (CPUs) and Graphics Processing Units (GPUs). Especially, GPUs are widely used for the execution of applications. However, CPUs and GPUs are not designed for machine learning algorithms, there have been several issues in terms of performance and power consumption. To resolve the problems, various machine learning accelerator designs have been proposed by researchers. One famous design is using a systolic array that has many small processing units which are only designed to perform Multiply-And-Accumulate (MAC) operations. These small processing units are connected only to their neighbor so that the data can be transferred from one processing unit to the other processing unit.
Our goal is to analyze the newly proposed machine learning accelerators. By doing this, we can find the performance bottleneck points or can detect the unnecessary processing execution cycles. Based on our analysis, we can propose advanced hardware accelerators for machine learning applications.
Parallel Programming
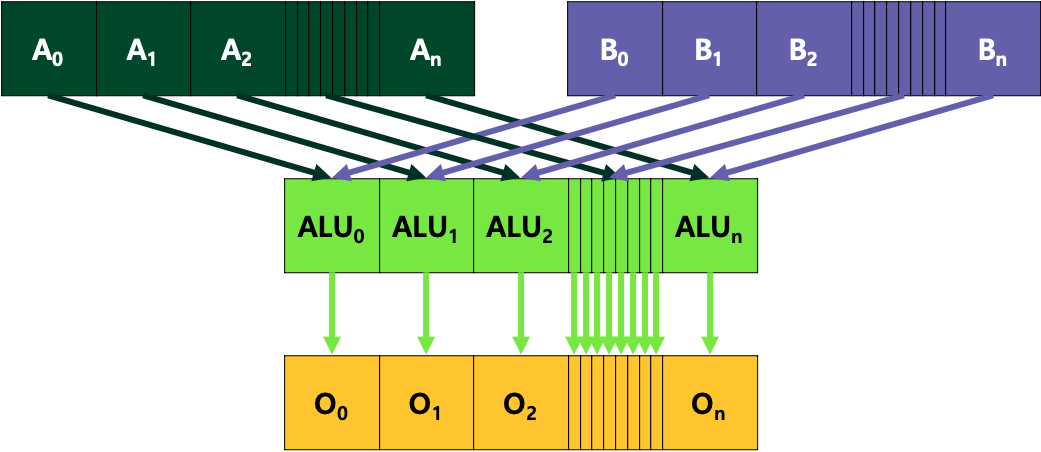 Single Instruction Multiple Data (SIMD) and Single Instruction Multiple Threads (SIMT) are execution models used in parallel computing. In these models, multiple threads (data) are executed in lock-step. These models are widely used for supercomputers because of their efficiency.
Single Instruction Multiple Data (SIMD) and Single Instruction Multiple Threads (SIMT) are execution models used in parallel computing. In these models, multiple threads (data) are executed in lock-step. These models are widely used for supercomputers because of their efficiency.
Intel and AMD CPUs have vector processors (SIMD) that can be used by Advanced Vector Extension (AVX) instructions. In the case of NVIDIA GPUs, Compute Unified Device Architecture (CUDA) allows software developers to use massively parallel SIMT processors for general purpose applications. The developers must have a decent knowledge of the vector processing units in order to create efficient applications. Our goal is to provide proper knowledge to software developers so that the developers can create efficient programs.
Computer Architecture
Computer Architecture is a set of rules which state how hardware is connected together in order to compute complicated applications. Researchers have proposed many different techniques such as branch predictions, speculative execution, out-of-order execution, memory pre-fetching, and more. We use C/C++/Python based cycle-accurate simulations to study the previously proposed techniques.
IP-CAL News!
-
[2026. 04.] Congratulation
The paper titled “Restructuring the Implicit GEMM Workflow for Complex-Valued Convolution” (Jaeeun, Eunbi, Jane) has been accepted to IEEE Access.
[2026. 02.] Welcome
Youngseo Hwang has joined our group as an undergraduate intern.
[2026. 01.] Welcome
Minkyoung Lee and Siyeon Kang have joined our group as undergraduate interns.
[2025. 10.] Congratulation
Jane has been selected as the best performer in the AI Convergence Project.
[2025. 08.] Congratulation
The papers titled “Understanding Distributed Training of Large Language Models with Unified Virtual Memory” (Jane, Eunbi) and “HALO: Hybrid Systolic Arrays via Logical Partitioning for Acceleration of Complex-Valued Neural Networks” (Ji Yeong, Eunbi, SungHee, Jane) have both been accepted to IISWC 2025.
[2025. 05.] Welcome
SeJin Park has joined our group as undergraduate interns.
[2025. 04.] Congratulation
Jiyeong has been selected as the best performer in the AI Convergence Project.
[2025. 03.] Congratulation
The paper titled "Hierarchical Traversal Stack Design Using Shared Memory for GPU Ray Tracing" by Eunsoo and Eunbi has been accepted to ISPASS 2025.
[2025. 02.] Congratulation
"Beyond VABlock: Improving Transformer Workloads through Aggressive Prefetching" by Jane and Ikyoung has been accepted in the Journal of Systems Architecture (JSA).
[2025. 01.] Welcome
Ga In Jeong and SungHee Yum have joined our group as undergraduate interns.
[2024. 11.] Congratulation
The paper titled "Warped-Compaction: Maximizing GPU Register File Bandwidth Utilization via Operand Compaction" by Eunbi has been accepted to HPCA 2025.
[2024. 09.] Welcome
Jane Rhee, Eunbi Jeong, Seonwoo Kim have started their master's degree.
[2024. 03.] Welcome
Eun Soo Jung and Jiyeong Yi have started their master's degree.
[2024. 02.] Congratulation
"Conflict-Aware Compiler for Hierarchical Register File on GPUs" by Eunbi and Eun Seong has been accepted in the Journal of Systems Architecture (JSA).
[2024. 01.] Welcome
Jiyeong Yi has joined our group as undergraduate interns.
[2023. 08.] Congratulation
Eunbi's first co-authored paper, "Triple-A," has been accepted in IEEE Embedded System Letters (ESL).
[2023. 07.] Congratulation
Eun Seong and Eunbi are honored with the Paper Award (우수논문상) at the 2023 Summer Annual Conference of IEIE.
[2023. 07.] Welcome
Ikyoung Choi has joined our group as undergraduate interns.
[2023. 04.] Welcome
Seonwoo Kim has joined our group as undergraduate interns.
[2023. 01.] Welcome
Jae Eun Hwang and Eunbi Jeong have joined our group as undergraduate interns.
[2022. 01.] Welcome
Eun Soo Jung, Yeonhee Jung, and Eun Seong Park have joined our group as undergraduate interns.
[2021. 07.] Welcome
Minyoung Lee, Jane Rhee, and Myeong Ji Kim have joined our group as undergraduate interns.